
코딩초보 김씨
[DL] 합성곱 신경망 CNN 본문
합성곱 신경망 CNN (Convolutional neural networks)
뇌가 물체를 인식할 때 동작하는 방식에서 영감을 얻은 모델. 이미지 처리에 사용
합성곱 연산 : 가중치를 공유하여 근처에 있는 뉴런들만 연산
이번에도 이 정도로만 알고, 자유 미션때 작성한 코드로 설명하겠다.
[ 데이터 수집 및 전처리 ]
#이미지 스크래퍼 라이브러리 설치
!pip install -q jmd_imagescraper
# directory 설정
base_dir = "/content/images"
# 수집할 이미지 개수
num_images_per_class = 500
# 이미지 수집
# res = duckduckgo_search(base_dir, "폴더명", "검색 키워드", max_results=num_images_per_class, uuid_names=False)
res = duckduckgo_search(base_dir, "Tulip", "flower Tulip", max_results=num_images_per_class, uuid_names=False)
res = duckduckgo_search(base_dir, "Rose", "flower Rose", max_results=num_images_per_class, uuid_names=False)
res = duckduckgo_search(base_dir, "Sunflower", "flower Sunflower", max_results=num_images_per_class, uuid_names=False)
res = duckduckgo_search(base_dir, "Mistflower", "flower Mistflower", max_results=num_images_per_class, uuid_names=False)
class_names = ["Tulip", "Sunflower", "Rose", "Mistflower"]
# 훈련, 검증, 테스트 분할을 위한 폴더 생성
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
for class_name in class_names:
train_class_dir = os.path.join(train_dir, class_name)
os.mkdir(train_class_dir)
validation_class_dir = os.path.join(validation_dir, class_name)
os.mkdir(validation_class_dir)
test_class_dir = os.path.join(test_dir, class_name)
os.mkdir(test_class_dir)
# 데이터를 훈련/검정/테스트 폴더로 분배
num_train = int(num_images_per_class*0.6) #전체 데이터의 60%를 훈련 데이터로
num_valid = int(num_images_per_class*0.2) #전체 데이터의 20%를 검증 데이터로
num_test = int(num_images_per_class*0.2) #전체 데이터의 20%를 테스트 데이터로
# 각 파일명 앞의 "0" 제거
for class_name in class_names:
class_dir = os.path.join(base_dir, class_name)
for filename in os.listdir(class_dir):
org_filename = os.path.join(class_dir,filename)
new_filename = os.path.join(class_dir,filename.lstrip("0"))
os.rename(org_filename, new_filename)
# 훈련 데이터를 train 폴더에 복사
for class_name in class_names:
class_dir = os.path.join(base_dir, class_name)
train_class_dir = os.path.join(train_dir, class_name)
fnames = ['{}.jpg'.format(i+1) for i in range(num_train)]
for fname in fnames:
src = os.path.join(class_dir, fname)
dst = os.path.join(train_class_dir, fname)
if os.path.isfile(src):
shutil.copyfile(src, dst)
# 검증 데이터를 valid 폴더에 복사
for class_name in class_names:
class_dir = os.path.join(base_dir, class_name)
valid_class_dir = os.path.join(validation_dir, class_name)
fnames = ['{}.jpg'.format(i+1) for i in range(num_train, num_train+num_valid)]
for fname in fnames:
src = os.path.join(class_dir, fname)
dst = os.path.join(valid_class_dir, fname)
if os.path.isfile(src):
shutil.copyfile(src, dst)
# 테스트 데이터를 test 폴더에 복사
for class_name in class_names:
class_dir = os.path.join(base_dir, class_name)
test_class_dir = os.path.join(test_dir, class_name)
fnames = ['{}.jpg'.format(i+1) for i in range(num_train+num_valid, num_train+num_valid+num_test)]
for fname in fnames:
src = os.path.join(class_dir, fname)
dst = os.path.join(test_class_dir, fname)
if os.path.isfile(src):
shutil.copyfile(src, dst)
방법 1. 기본 CNN 모델
[ 0. dataset generator 정의 ]
# 데이터셋 제네레이터 정의
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=40)
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=40)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=40)
# 미니 배치 데이터 크기 및 레이블 크기 확인
for data_batch, labels_batch in train_generator:
print('배치 데이터 크기:', data_batch.shape)
print('배치 레이블 크기:', labels_batch.shape)
break
[ 1. 모델 생성 및 확인 ]
* Conv2D Layer : 합성곱 연산 층
* Pooling Layer : 이미지 크기를 줄이는 층. 이미지 왜곡에도 비슷하며 과적합 방지(최대/평균)
# 입력 데이터의 모양이 (150,150,3)과 동일한지, 최종 출력층의 크기가 클래스 개수와 동일한지 확인합니다.
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(40, (3, 3), activation='relu', padding='same', input_shape=(150, 150, 3)))
model.add(tf.keras.layers.MaxPooling2D((3, 3)))
model.add(tf.keras.layers.Conv2D(70, (3, 3), activation='relu', padding='same'))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Conv2D(100, (3, 3), activation='relu', padding='same'))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dropout(0.6))
model.add(tf.keras.layers.Dense(100, activation='relu'))
model.add(tf.keras.layers.Dense(4, activation='softmax'))
model.summary()
| Parameter | 의미 |
| (3, 3) | 필터의 크기 3*3 |
| padding='same' | 패딩의 사이즈는 출력값과 입력값의 크기가 동일하도록 패딩이란? 가장자리 데이터 정보 손실을 막기위해 데이터 주변에 0으로 둘러 싸는 것 |
| stride | 필터가 입력 이미지에서 이동하는 칸 수. |
| input_shape=(150, 150, 3) | 이미지가 150*150 크기인데, 컬러 이미지기 때문에 채널이 "3"개라는 의미 |
[ 2. 모델 컴파일 ]
# 팁: loss는 'categorical_crossentropy'를 사용합니다
# (데이터셋 제네레이터는 기본적으로 클래스 종류가 여러개인 상황인 'categorical'로 정의되어 있음)
model.compile(loss='categorical_crossentropy',
optimizer='Adam',
metrics=['accuracy'])
[ 3. 모델 학습 ]
history = model.fit(
train_generator,
epochs=15,
validation_data=validation_generator)
[ 4. 결과 확인 ]
hist = history.history
x_arr = np.arange(len(hist['loss'])) + 1
fig = plt.figure(figsize=(12, 4))
ax = fig.add_subplot(1, 2, 1)
ax.plot(x_arr, hist['loss'], '-o', label='Train loss')
ax.plot(x_arr, hist['val_loss'], '--<', label='Validation loss')
ax.set_xlabel('Epoch', size=15)
ax.set_ylabel('Loss', size=15)
ax.legend(fontsize=15)
ax = fig.add_subplot(1, 2, 2)
ax.plot(x_arr, hist['accuracy'], '-o', label='Train acc.')
ax.plot(x_arr, hist['val_accuracy'], '--<', label='Validation acc.')
ax.legend(fontsize=15)
ax.set_xlabel('Epoch', size=15)
ax.set_ylabel('Accuracy', size=15)
plt.show()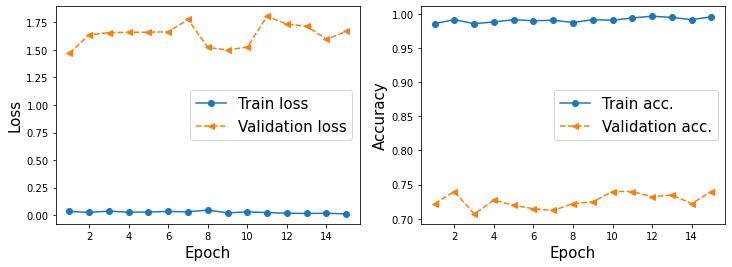
test_results = model.evaluate(test_generator)
print('\n테스트 정확도 {:.2f}%'.format(test_results[1]*100))=> 테스트 정확도 75.57%
방법 2. 이미지 증식
[ 0. 이미지 전처리 및 dataset generator 정의 ]
from tensorflow.keras.preprocessing.image import ImageDataGenerator
data_aug_gen = ImageDataGenerator(
rescale=1./255, # 데이터 0~1사이의 값 갖도록 정규화
rotation_range=40, # 랜덤하게 사진을 회전시킬 각도 범위(0-180 사이)
width_shift_range=0.2, # 사진을 수평으로 랜덤하게 평행 이동시킬 범위(전체 넓이에 대한 비율).
height_shift_range=0.2, # 사진을 수직으로 랜덤하게 평행 이동시킬 범위(전체 높이에 대한 비율).
shear_range=0.2, # 사진을 랜덤하게 전단(비틀기)할 각도 범위
zoom_range=0.2, # 사진을 랜덤하게 확대할 범위
horizontal_flip=True, # 랜덤하게 이미지를 수평으로 반전
fill_mode='nearest') # 회전이나 가로/세로 이동으로 인해 새롭게 생성해야 할 픽셀을 채우는 방법.
# 데이터 증식하는 data_aug_gen으로 train data augmented generator 정의
train_aug_generator = data_aug_gen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=40,
class_mode='categorical')
[ 1. 모델 생성 ]
구조는 기본 모델과 동일하게 생성함
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(40, (3, 3), activation='relu', padding='same', input_shape=(150, 150, 3)))
model.add(tf.keras.layers.MaxPooling2D((3, 3)))
model.add(tf.keras.layers.Conv2D(70, (3, 3), activation='relu', padding='same'))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Conv2D(100, (3, 3), activation='relu', padding='same'))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dropout(0.6))
model.add(tf.keras.layers.Dense(100, activation='relu'))
model.add(tf.keras.layers.Dense(4, activation='softmax'))
[ 2. 모델 컴파일 및 학습 ]
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
history = model.fit(
train_aug_generator,
epochs=15,
validation_data=validation_generator)
[ 3. 결과 확인 ]
test_results = model.evaluate(test_generator)
print('\n테스트 정확도 {:.2f}%'.format(test_results[1]*100))=> 테스트 정확도 77.08%
방법 3. 트랜스퍼 러닝 (VGG16 모델 사용)
[ 0. VGG 16 모델 불러오기 ]
from tensorflow.keras.applications import VGG16
conv_base = VGG16(weights='imagenet', #모델을 초기화할 가중치 체크포인트를 지정
include_top=False, #신경망 최상위의 분류기를 불러올지 여부 결정 (기본은 Imagenet의 1000개 클래스 구분 분류기)
input_shape=(150, 150, 3)) #입력 이미지 크기
[ 1. end to end 모델 생성 ]
end to end : 추가한 모델의 가중치만 업데이트하여 학습
미세조정 end to end : 베이스 모델의 가중치의 일부도 함께 학습
model = tf.keras.models.Sequential()
model.add(conv_base) # 베이스 모델
#분류 모델 추가
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(100, activation='relu', input_dim=4 * 4 * 512))
model.add(tf.keras.layers.Dropout(0.6))
model.add(tf.keras.layers.Dense(4, activation='softmax'))
# VGG 16의 가중치는 train 불가하도록 False로 지정
conv_base.trainable = False
model.summary()
[ 2. 모델 컴파일 및 학습 ]
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(
train_aug_generator, #학습 데이터 증식 제네레이터
epochs=15,
validation_data=validation_generator)
[ 3. 결과 확인 ]
test_results = model.evaluate(test_generator)
print('\n테스트 정확도 {:.2f}%'.format(test_results[1]*100))=> 테스트 정확도 83.12%
[ 4. 미세조정 end to end 모델 설정 ]
model = tf.keras.models.Sequential()
model.add(conv_base) # 베이스 모델
#분류 모델 추가
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(100, activation='relu', input_dim=4 * 4 * 512))
model.add(tf.keras.layers.Dropout(0.6))
model.add(tf.keras.layers.Dense(4, activation='softmax'))
#베이스 모델의 block5(3개의 합성곱층+풀링)만 동결 해제
conv_base.trainable = True
for layer in conv_base.layers:
if layer.name in ['block5_conv1','block5_conv2','block5_conv3']:
layer.trainable = True
else:
layer.trainable = False
conv_base.summary()
model.summary()
[ 5. 모델 컴파일 및 학습 ]
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-5), # 기존에 학습된 가중치를 과하게 조정하지 않기 위해 학습률을 낮춤 (기본 = 1e-3)
metrics=['accuracy'])
history = model.fit(
train_aug_generator, #학습 데이터 증식 제네레이터
epochs=15,
validation_data=validation_generator)
[ 6. 결과 확인 ]
test_results = model.evaluate(test_generator)
print('\n테스트 정확도 {:.2f}%'.format(test_results[1]*100))=> 테스트 정확도 87.66%
결론 : 내가 용써서 새로운 모델을 만드는 것 보다 기존 좋은 성능의 모델을 가져다가 쓰는 것이 훨~ 씬 정확도가 높다!
'Python > Deep Learning' 카테고리의 다른 글
| [DL] 딥러닝 개요 - 기초 모델 (0) | 2021.07.10 |
|---|
