
코딩초보 김씨
[ML] 지도학습 본문
머신러닝은 크게 1)지도학습, 2)비지도학습, 3)강화학습으로 나눌 수 있으며,
지도학습은 분류, 회귀로 나뉘어진다.
비지도학습의 경우 군집화까지 배워서 추후 더 추가할 예정이다.
먼저 분류와 회귀의 차이점은,
0 또는 1처럼 이산 값으로 label이 정해진다면 분류, 키나 몸무게처럼 연속 값이면 회귀이다.
오늘은 지도학습의 분류에 대해서 정리하는 글을 작성할 것이다.

분류 (Classifier)
| 데이터 | Feature와 Label로 이루어진 데이터 세트 필요 |
| 알고리즘 | 데이터 세트 분리(train_test_split) → 트레인데이터로 모델 학습(fit) → 테스트데이터로 예측(predict) → 평가(accuracy_score) + 교차검증 |
| 모델 종류 | DecisionTree, RandomForest, GradientBoosting, SVC 등 |
| 성능 평가 지표 | 정확도, 오차행렬, 정밀도, 재현율, F1 score, ROC AUC |
[ 데이터 ]
꽃잎 길이와 너비처럼 정보(힌트)가 되는 것이 피처(Feature)
꽃 종류(정답)가 레이블(Label)이다.
위에서 말한 것처럼 분류는 이산 값을 예측하기 때문에 아래와 같은 데이터 세트가 꼭 필요하다.

[ 알고리즘 ]
데이터 세트 분리(train_test_split) → train data로 모델 학습(fit) → test data로 예측(predict) → 평가(accuracy_score)
# iris 데이터 로드
iris_df = pd.DataFrame(iris_data.data, columns=iris_data.feature_names)
# 'target' column 생성
iris_df['target'] = iris_data.target
# 피쳐 정의
ftr_df = iris_df.iloc[:, :-1]
# 타겟 정의
tgt_df = iris_df.iloc[:, -1]
# train_test_split 함수 : 학습/테스트 데이터 분리
X_train, X_test, y_train, y_test =train_test_split(ftr_df, tgt_df, test_size=0.3, random_state=121)
# decisiontree 모델 정의
dt_clf = DecisionTreeClassifier( )
# train 데이터로 학습
dt_clf.fit(X_train, y_train)
# test 데이터로 예측
pred = dt_clf.predict(X_test)
# 평가
print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))
+ 교차 검증 : K-fold, stratified K-fold, cross_val_score, GridSearchCV
정해진 데이터를 고정된 train, test로 모델을 튜닝하면 해당 test데이터에만 잘 맞는 과적합 가능성이 있다.
이를 방지하기 위해 교차 검증이 필요하다.
데이터 세트를 k개로 나누고 학습 예측 평가 진행 * k번 반복
(이 블로그에 잘 정리되어있으니 깜빡할 때마다 참고하자!)
1) K-fold : 불균형한 데이터에는 적용이 어려움
2) stratified K-fold : 레이블 데이터를 균형하도록 섞어서 데이터를 나눔
3) cross_val_score : 폴드 세트 추출, 학습 및 예측, 평가 과정들을 한 번에 수행. 아래 코드 한 줄로 끝남
scores = cross_val_score(모델, data, label, scoring='accuracy', cv=?)4) GridSearchCV : 교차 검증 + 하이퍼 파라미터 튜닝
# hyper-parameter 들을 딕셔너리 형태로 설정
parameters = {'max_depth':[1, 2, 3, 4], 'min_samples_split':[2, 3, 4]}
# 테스트 수행 설정.
# refit=True 가 default : 가장 좋은 파라미터 설정으로 모델 재 학습
grid_dtree = GridSearchCV(dtree, param_grid=parameters, cv=3, refit=True, return_train_score=True)
# Train 데이터로 하이퍼 파라미터들을 순차적으로 학습/평가
grid_dtree.fit(X_train, y_train)
# GridSearchCV 결과는 cv_results_ 라는 딕셔너리로 저장됨. 이를 DataFrame으로 변환해서 확인
scores_df = pd.DataFrame(grid_dtree.cv_results_)
scores_df[['params', 'mean_test_score', 'rank_test_score',
'split0_test_score', 'split1_test_score', 'split2_test_score']]
# y_test로 predict (refit=True로 설정된 GridSearchCV 객체가학습이 완료된 Estimator를 내포하고 있음)
pred = grid_dtree.predict(X_test)
# 평가
accuracy_score(y_test, pred)
[ 모델 종류 ]
1. Decision Tree : 스무고개 예/아니오처럼 조건에 맞게 나누는 모델 + 피처 중요도 확인 가능★
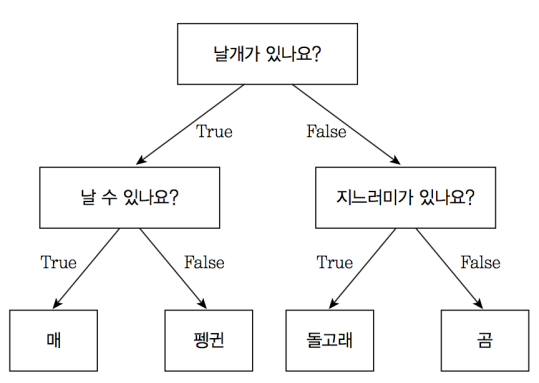
*Bagging, Boosting : 앙상블의 종류
앙상블이란? 다수의 classifier를 생성하고 그 예측을 결합하여 보다 정확한 최종 예측을 도출하는 기법
Bagging이란? 다수의 약한 모델을 이용하여 Bootstrapping 데이터를 학습하고, 모든 모델의 예측 결과를 평균하여 예측
보통 DecisionTree classifier 여러 개를 각각 다른 subset 데이터로 학습/예측시킨 것이 RandomForest임
Boosting이란? 다수의 약한 모델을 순차적으로 학습/예측하며 잘못 예측한 데이터에 가중치를 부여하여 오류를 개선
2. *Bagging : Random Forest ( =bagging 한 Decision Tree)
예시 : get_human_dataset()
# train, test 데이터 분리
X_train, X_test, y_train, y_test = get_human_dataset()
# 모델 객체 생성
rf_clf = RandomForestClassifier(random_state=0)
# 학습
rf_clf.fit(X_train , y_train)
# 예측
pred = rf_clf.predict(X_test)
# 평가
accuracy_score(y_test , pred)
3. *Boosting : Adaboost, GBM, XGBOOST, Lightgbm 등
1) Adaboost(Adaptive Boosting) : 잘못 분류되는 예제에 가중치를 주어 점차적으로 모델을 학습시키면서 결과 예측
2) GBM(Gradient Boosting Machine) : 경사 하강법으로 가중치 업데이트하여 점차적으로 모델을 학습시키면서 결과 예측. (느림)
3) XGBoost : GBM 대비 빠름, 과적합 규제 기능, Tree Pruning, 조기 중단
4) LightGBM : XGBoost 대비 빠름(성능은 비슷)
예시 : 위스콘신 Breast Cancer
# train, test 데이터 분리
X_train, X_test, y_train, y_test=train_test_split(ftr, target, test_size=0.2, random_state=156)
# n_estimators 400번 반복하도록 설정.
lgbm_wrapper = LGBMClassifier(n_estimators=400)
# 원래 evals에 검증 데이터 셋을 별도로 둬야하지만 여기서는 테스트 데이터 사용
evals = [(X_test, y_test)]
# early_stopping_rounds으로 조기중단 기능 설정
lgbm_wrapper.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="logloss",
eval_set=evals, verbose=True)
# 예측
preds = lgbm_wrapper.predict(X_test)
# 평가
accuracy_score(y_test , pred)
[ 성능 평가 지표 ]
1. 정확도 : 정답 수 / 전체 예측 수 = (TN + TP) / (TN + TP + FN + FP)
accuracy_score(y_test , pred)2. 오차 행렬 : 예측 오류 확인을 위한 지표

*정밀도와 재현율은 trade-off 관계
3. *정밀도 = TP / (TP + FP)
precision_score(y_test , pred)4. *재현율 = TP / (TP + FN)
recall_score(y_test , pred)5. F1 score : 정밀도와 재현율이 비슷한 값을 가질 때 가장 높은 값. 정밀도와 재현율이 적정한지 판단 기준이 됨
f1_score(y_test , pred)
6. ROC곡선, AUC 스코어 : AUC 스코어는 ROC 곡선 아래 면적이며, 1에 가까울수록 좋다

roc_auc_score(y_test , pred)
< 모델의 평가지표들을 한 번에 보여주는 함수 !! >
def clf_eval_total(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test,pred)
roc_auc = roc_auc_score(y_test, pred_proba)
print(confusion)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\
F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc), '\n')'Python > Machine Learning' 카테고리의 다른 글
| [ML] 데이터 전처리 - 선형 차원 축소 (0) | 2021.06.14 |
|---|---|
| [ML] 비지도학습 - Clustering (군집화) 중 k-Means (0) | 2021.06.09 |

