
코딩초보 김씨
[1] 네이버 호텔 크롤링 본문
사람마다 여행에서 중요하게 생각하는 요소가 모두 다르다.
내가 가장 중요하게 생각하는 요소는 "숙소" 이다.
그래서 네이버 호텔 페이지의 호텔을 크롤링하여, 텍스트 분석을 통한 추천 시스템을 만들어보고싶은
큰 꿈을 가지고 시작해보려고 한다.
첫번째는 네이버 호텔의 호텔 이름과 URL 크롤링!!
1. 라이브러리 import
import sys
import os
import pandas as pd
import numpy as np
import time # 파이썬 너무 빨라서 꼬이는 것 방지.
from bs4 import BeautifulSoup # html 데이터를 전처리
from selenium import webdriver # 웹 브라우저 자동화
from tqdm import tqdm_notebook # for문 돌릴 때 진행상황을 %게이지로
from selenium.webdriver.common.keys import Keys # 엔터키 누르기
2. 크롬 드라이버 실행 및 '네이버 호텔' 홈페이지 열기
path = "chromedriver.exe" # 크롬드라이버와 파이썬 저장위치 같아야함
driver = webdriver.Chrome(path) # selenium에서 불러온 기능
driver.get('https://hotel.naver.com/hotels/main') # 사이트 주소는 네이버
time.sleep(2) # 2초간 정지
3. 키워드 지정 및 검색
# 데이터 수집할 키워드 지정
keyword = '제주도'
# '검색'란에 제주도 입력
element = driver.find_element_by_id("hotel_search")
element.send_keys(keyword) # keyword는 위에서 입력한 키워드
time.sleep(1)
# 엔터키 누르기
element.send_keys(Keys.ENTER)
time.sleep(1)
# '호텔 검색' 누르기
driver.find_element_by_css_selector(".btn_search_confirm.sp_hotel").click()
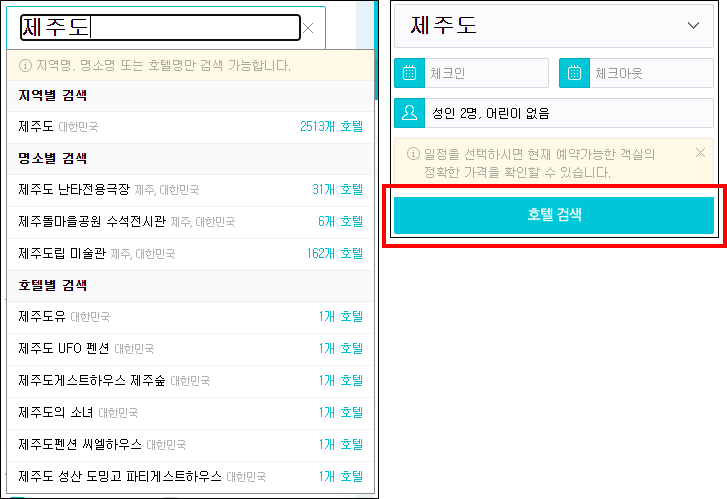
time.sleep(1)검색란에 제주도 입력 후 엔터키만 누르면, 호텔 검색이 안되고 아래 사진처럼 리스트가 쭉 늘어나있다.
그래서 호텔 검색을 별도로 눌러주어야 했다.
4. 대망의 데이터 수집!! 이었지만 실패했다..
# 데이터 담을 리스트 정의
naver_hotels_url_list = []
naver_hotels_name_list = []
# 호텔 url 데이터 수집
hotels_raw = driver.find_elements_by_css_selector("____")
# url이 잘 수집되었는지 확인
print(hotels_raw[0].get_attribute('href'))호텔 url 데이터 수집 부분에서 홈페이지 요소 확인을 해보니 html 주소가 없었다 !!!!!!
(강사 선생님도 다른 홈페이지 크롤링하라구 하심!ㅋㅋ)
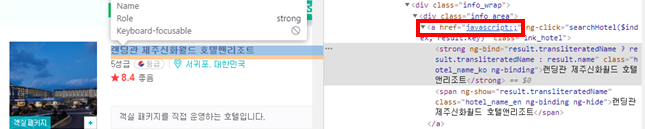
나의 야심찬 첫 번째 프로젝트는 처음부터 왠지 험난할 것 같은 느낌이 든다..
끝낼 수 있겠지??
'김초보의 프로젝트 > 네이버호텔 추천시스템' 카테고리의 다른 글
| [5] 네이버 호텔 크롤링 5 (0) | 2021.05.13 |
|---|---|
| [4] 네이버 호텔 크롤링 4 (1) | 2021.05.12 |
| [3] 네이버 호텔 크롤링 3 (0) | 2021.05.12 |
| [2] 네이버 호텔 크롤링 2 (0) | 2021.05.11 |
| [맛보기] 네이버, 다음 크롤러 (0) | 2021.05.06 |
'김초보의 프로젝트/네이버호텔 추천시스템' Related Articles
more



Comments